

When I was temporary working at my former university UPC (Universitat politècnica de Catalunya) in the TALP department (Center for Language and Speech Technologies and Applications), I found myself in the following situation:
My employers had a lot of python code creating matrices and stuff saved to .npy (numpy files) but wanted to speed up their processes.
I thought about loading those files in existing C code, to effectively use the GPU with OpenGL/CUDA. And once everyone was convinced, I spent some time developing a small library to do so, in the following post you will find an explanation of the numpy format and the code for the C library.
TL;DR
I am not interested in this, just download!
 ..
..
NOTE from the future:
The code was lost 😦 but there’s a new implementation by Øystein Schønning-Johansen. Thanks!
..
It already exists
I googled a bit and voilà!, cnpy is there doing the work. The generic definition claims
library to read/write .npy and .npz files in C/C++
But reading a little bit more I only see C++ code around.
I found it interesting, so my next step was to create a small library in plain C for our internal use.
The Objective
My first objective is simple and single minded. We work with numpy data in 1 and 2 dimensions with dtype float32. So i want a library to load this into C.
The Format
This is quite easy because the .npy format is simple and clearly defined in the specification.
It consists of a basic header and the data directly dumped.
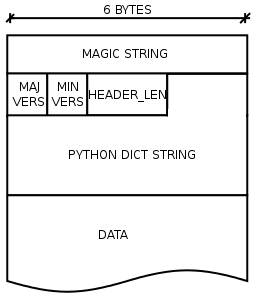
The .npy format
| Item | Size | Description |
|---|---|---|
| MAGIC_STRING | 6 | The magic string for a .npy file is always the same “\x93NUMPY” |
| Major version | 1 | Major version number |
| Minor version | 1 | Minor version number |
| HEADER_LEN (h) |
2 | Size of the following header |
| PYTHON DICT STRING | h | Text representing a python dictionary |
| DATA | EOF | Data in either C or FORTRAN order. |
The dictionary contains information about the data that follows. It is saved as a string, which makes its access more cumbersome. The dictionary contains:
- descr: an object that can be passed to
numpy.dtype. - fortran_order: if True, the matrix is saved in column-major order. As FORTRAN likes it. The default is False.
- shape: Describes the dimensions of the matrix

Numpy dump
Implement
It won’t be totally functional, but I will have functions to read all the items of the header, and the data that follows.
Even if I check the dtype, I will not use it, so far my types are only float32 and I am not aiming to a full library. In the case that somebody needs other types I hope that this post will teach how to do it.
Reading the data into a plain array is enough, but I will also implement a simple function to generate a matrix (float32_t** matrix)
MAGIC
First things first, retrieve the MAGIC string. I allocate a new char* to fill with the magic string. rewind the FILE pointer to the beginning of the file and read the first 6 characters.
#define MAGIC_SIZE 6
#define NPYERR_NOMEM 8
char* retrieve_magic(FILE* fp){
char* magic = malloc(sizeof(char) * MAGIC_SIZE);
if(magic == NULL){
NPYERRNO = NPYERR_NOMEM;
return NULL;
}
rewind(fp);
int nread = fread(magic, sizeof(char),
MAGIC_SIZE, fp);
if(!nread) NPYERRNO = NPYERR_FREAD;
return magic;
}
This is important to double check that the file is indeed a numpy file. This magic should be “\x93NUMPY”.
Also note that I am allocating memory and returning a pointer to it. The user is responsible for freeing this memory.
int main(){
char filename[] = "whatever filename";
FILE* fp;
fp = fopen(filename, "r");
char* magic = retrieve_magic(fp);
if(magic == NULL)
return 1;
free(magic);
fclose(fp);
return 0;
}
Header length
To retrieve the dictionary, we need to know the length of it. This is something to be done directly, just seeking the correct byte numbers and reading them.
uint16_t retrieve_HEADER_LEN(FILE *fp){
uint16_t val;
int err = fseek(fp, HEADER_LEN_SEEK, SEEK_SET);
if (err)
return -1;
int nread = fread(&val, sizeof(uint16_t), 1, fp);
if(!nread) NPYERRNO = NPYERR_FREAD;
return val;
}
Dictionary as char*
The most important part is the dictionary, and within it the type and the shape. As I commented before I won’t bother right now with the type, but the shape is important as it will determine how to make sense of the DATA blob.
Let’s define a constant with the position of the dictionary
#define DICT_SEEK 10
The dictionary size will be the size defined by HEADER_LEN, that is already extracted on the previous function.
uint16_t hsize = retrieve_HEADER_LEN(fp);
We will need an equally long string to hold the dictionary. Note the +1 to store the end of string special character.
char* dict = malloc(sizeof(char) * (hsize + 1));
After that is just a matter of reading that amount of data.
#define DICT_SEEK 10
#define NPYERR_FREAD 6
char* retrieve_python_dict(FILE* fp){
uint16_t hsize = retrieve_HEADER_LEN(fp);
char* dict = malloc(sizeof(char) * (hsize + 1));
if(dict == NULL){
NPYERRNO = NPYERR_NOMEM;
return NULL;
}
int err = fseek(fp, DICT_SEEK, SEEK_SET);
if(err == -1) NPYERRNO = NPYERR_FSEEK;
int nread = fread(dict, sizeof(char), hsize, fp);
if(!nread) NPYERRNO = NPYERR_FREAD;
dict[hsize] = '\0';
return dict;
}
The sizes from the dictionary
The dictionary contains text data that has to be transformed. The sizes are represented by a string similar to (40,5000), or (40,). There is also the special case (,) that means 1 value.
My original implementation was using strtok. But probably I have no idea how to use it, and even if it worked I did not like how it looked and how Valgrind complained :-). I changed to strspn. This function computes the size of a segment of a string containing only a specific set of characters.
My specific set of chars is:
char *numbers = "0123456789 "
The idea is to keep advancing the pointer in the string until no more number characters are found.
For this to work, the pointer has to start in the position just after “(” on the dictionary. I create a new pointer pointing to that position using strchr and strstr
char* sizstart = strchr(strstr(dictstring, "'shape'"),'(');
sizstart++
For each number that I find, I copy the number string to a temporal string with strncpy and perform an atoi.
len = strspn(sizstart, numbers);
strncpy(sizestr, sizstart, len);
sizes[i] = (uint32_t)atoi(sizestr);
When no more number strings are found I add the last item. Just as convenience a -1 will be at the end of the array to mark that there are no more items. Another way would be to have an inout parameter to return the size of that array.
uint32_t* get_shape(char* dictstring){
char* sizstart = strchr(strstr(dictstring, "'shape'"),'(');
sizstart++; //remove the (
//Anything bigger than 5 dimensions will break
uint32_t* sizes = malloc(sizeof(uint32_t) * 5);
if(sizes == NULL){
NPYERRNO = NPYERR_NOMEM;
return NULL;
}
char *numbers = "0123456789 ";
size_t len;
int i = 0;
//Allocate a temporal string to hold results
char* sizestr = calloc(100, sizeof(char));
while((len = strspn(sizstart, numbers))!= 0){
strncpy(sizestr, sizstart, len);
sizes[i] = (uint32_t)atoi(sizestr);
sizstart += len+1;
i++;
}
sizes[i] = -1; //The array finishes with -1
free(sizestr);
return sizes;
}
This is not the safest way to do it, simply my first attempt. It works for well-formed strings, but ill-formed stuff will probably fail.
Load the DATA
I skip other parts of the python dictionary as they are not important for me right now, but it would be almost the same. Knowing the HEADER_LEN we can retrieve the data.
There are some assumptions here:
- fortran_order = False
- numpy dtype is float32
If fortran_order was true, the matrix would be stored in column-major order. C is row-major. In that case, we would not be able to retrieve the data so fast.
If the dtype is not float32 we have a type mismatch that will lead to incorrect data.
To retrieve the data we only need the start byte and the file size.
The file size can be obtained with the following function, using fseek and ftell.
long fsize(FILE *fp){
fseek(fp, 0, SEEK_END);
long size = ftell(fp);
fseek(fp, 0, SEEK_SET);
return size;
}
The start point is just the header size before the data:
The +4 represents the already discussed 4 bytes: major version (1byte), minor version (1byte) and HEADERLEN (2 bytes)
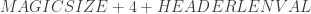
float32_t* retrieve_npy_float32(FILE* fp){
uint16_t hsize = retrieve_HEADER_LEN(fp);
int skstart = MAGIC_SIZE + 4 + hsize;
long size = fsize(fp);
int err = fseek(fp, skstart, SEEK_SET);
float32_t* array_f32t = malloc(size - skstart);
if (array_f32t == NULL){
NPYERRNO = NPYERR_NOMEM;
return NULL;
}
int nread = fread(array_f32t, sizeof(float32_t), (size - skstart)/sizeof(float32_t), fp);
if(!nread) NPYERRNO = NPYERR_FREAD;
return array_f32t;
}
And that’s it. With that set of functions we can retrieve data from a .npy file saved with the dtype float32. If you want to check more functionality just get the file from the end of the post, it has the full source code with all that I implemented.
Be aware that it a non-finished work, so it has rough edges that I did not clean. You can do it 🙂
Further Work
This just works for what I need, but that is not enough. There is a lot to support, and I’ve done so little.
- More .npy dtypes. At least the basic ones: floats and ints
- Support fortran_order
- Support Endianness
Conclusions
Numpy is a library that I’ve been using this past 4 months. Saving and loading to .npy is easy.
I am glad that the developers decided to save the data in such direct way, I only dislike how the python dictionary is saved as a string, but it’s quite understandable for the python world.
Numpy has a lot of types, so it’s not easy to support everything directly, but it should not be very difficult either to support the most widely used types, I assume that those are floats (32 and 64) and ints (32 and 64).
Download
My idea was to put the file directly into wordpress.com. But they don’t accept tarballs.
I’ve been tempted to rename the tarball to .tar.gz.jpeg (hey, it works). But It looks dirty and suspicious
so I appended it under my sourceforge profile.
..
NOTE from the future:
As you can see in the comments, this file is no longer available to download 😦 sourceforge removed the user spaces and did not respond my email about it. This was done at an office where I don’t work anymore, so there’s no means so far to recover.
..
References
The .npy format ⇒GO
Man pages (for all the functions used) ⇒GO

Hey, I am interested in this project, but in SourceForge there is no file to download.
Hola Arnau,
I am having a look,
I quickly checked sourceforge but I can’t find the file anywhere
Hi! I found out that this was exactly what I needed, but since the code was gone from SF, I just wrote my own. Find my library on github:
https://github.com/oysteijo/c_npy
Thanks man!
I updated the post to link to your implementation so anybody else getting into this “cul de sac” can find somewhere else to go 😀
I did not try it though 😛